PyTorchのpermuteメソッドとは?- ディメンションの並び替えを簡単に行う方法
PyTorchは、ディープラーニングにおける人気のあるフレームワークの一つです。その柔軟性と高速な計算性能により、多くのデータサイエンティストや機械学習エンジニアに愛用されています。PyTorchには多くの便利な関数とメソッドがありますが、その中でもpermuteメソッドはディメンションの並び替えを行う際に非常に便利な機能です。
permuteメソッドとは?
permuteメソッドは、テンソル(Tensor)のディメンション(次元)を並び替えるためのメソッドです。例えば、3次元のテンソルを取り扱っている際に、ディメンションの並びを変更したい場合に非常に役立ちます。このメソッドを使用することで、簡単かつ効率的にディメンションを入れ替えることができます。
permuteメソッドの使用例
以下の例を通じて、permuteメソッドの使用方法を理解しましょう。例として、3次元のテンソルを作成してディメンションの並び替えを行います。
import torch # 3次元のテンソルを作成 x = torch.tensor([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]) print(x.size())
出力:
torch.Size([2, 2, 3])
上記のコードでは、xという3次元のテンソルを作成しました。このテンソルのディメンションは(2, 2, 3)です。
このテンソルに対して、permute()メソッドを用いてディメンションの並び替えを行います。
permuteメソッドの引数には、permute(2, 0, 1)のように、新しいディメンションの並びを指定します。
# ディメンションの並び替え x_permuted = x.permute(2, 0, 1) print(x_permuted.size()) print(x_permuted)
出力
torch.Size([3, 2, 2]) tensor([[[ 1, 4], [ 7, 10]], [[ 2, 5], [ 8, 11]], [[ 3, 6], [ 9, 12]]])
ディメンションが(2, 2, 3)から(3, 2, 2)に変わり、それぞれの要素が正しく並び替えられました。
もともと(2, 2, 3)だったものに対して、.permute(2, 0, 1)とすることで、
0番目の次元は、もともと2番目だった"3"
1番目の次元は、もともと0番目だった"2"
2番目の次元は、もともと1番目だった"2"
が入ることで、(3, 2, 2)となります。
まとめ
permuteメソッドは、PyTorchのテンソル操作においてディメンションの並び替えを簡単に行うことができる便利な機能です。特に、畳み込みニューラルネットワークなどのディープラーニングモデルを構築する際に、ディメンションの順序を変更する必要がある場合に非常に便利です。ぜひpermuteメソッドを活用して、効率的なテンソル操作を行ってみてください!
pandasでjsonファイルを読み込む方法
JSON(JavaScript Object Notation)は、データを表現するための軽量なデータ形式です。 このJSONファイルをPandasで読み込む方法は至って簡単で、"read_json()"メソッドを使うだけです。 以下に例を示します。
import pandas as pd import json s = '{"col1":{"row1":"A","row2":"B","row3":"C"},"col2":{"row1":"あ","row2":"い","row3":"う"}}' df_s = pd.read_json(s) print(df_s) # 出力 col1 col2 row1 A あ row2 B い row3 C う
このように簡単にJSONファイルを読み込むことができます。
また、Pandasは、JSONデータが単一のオブジェクト(辞書形式)や配列(リスト形式)である場合にも適用することができます。以下に、それぞれの例を示します。
1. JSONデータが単一のオブジェクト(辞書形式)である場合:
import pandas as pd import json # JSONデータ(辞書形式) data = { "name": "John", "age": 30, "city": "Tokyo" } # JSONデータをPandasのDataFrameとして読み込む dataframe = pd.DataFrame.from_dict(data, orient='index').T
上記の例では、pd.DataFrame.from_dict()関数を使用して、辞書形式のJSONデータをDataFrameに変換しています。orient='index'を指定することで、辞書のキーが列名になります。
2. JSONデータが配列(リスト形式)である場合:
import pandas as pd import json # JSONデータ(リスト形式) data = [ {"name": "John", "age": 30, "city": "Tokyo"}, {"name": "Emily", "age": 25, "city": "New York"}, {"name": "Tom", "age": 35, "city": "London"} ] # JSONデータをPandasのDataFrameとして読み込む dataframe = pd.DataFrame(data)
上記の例では、単純なリスト形式のJSONデータを直接pd.DataFrame()関数に渡すことで、DataFrameに変換しています。
以上が、Pandasを使用してJSONファイルを読み込む手法の例です。実際の使用に応じて、適切な方法を選択して使用してみてください!
Google Search Consoleを導入してみた。導入手順まとめ
Google Search Consoleとは?
ブログに関して色々調べてみると、Google Search Consoleを導入した方がいいという情報が多かったので、試しに導入してみました。
Google Search Consoleを導入すると大きく3つの情報が得られるみたいです。
1. ブログ記事がGoogleに登録されているか
2. どのような検索ワードで検索されたのか
3. 検索順位
いろいろと記事を書くなら、これらの情報が可視化された方が面白そうだなと思って、今回導入することにしました。
是非、ブログを書いている方は参考にしてみてください。
Google Search Consoleにブログを登録
こちらから、Google Search Consoleにアクセス。
 「今すぐ開始」をクリック
「今すぐ開始」をクリック
 右側の「URLプレフィックス」をクリック。
右側の「URLプレフィックス」をクリック。
その後、URLの入力欄に、ご自身のブログURLを入力し、「続行」をクリック。
続いて、ブログの所有権の確認を行います。
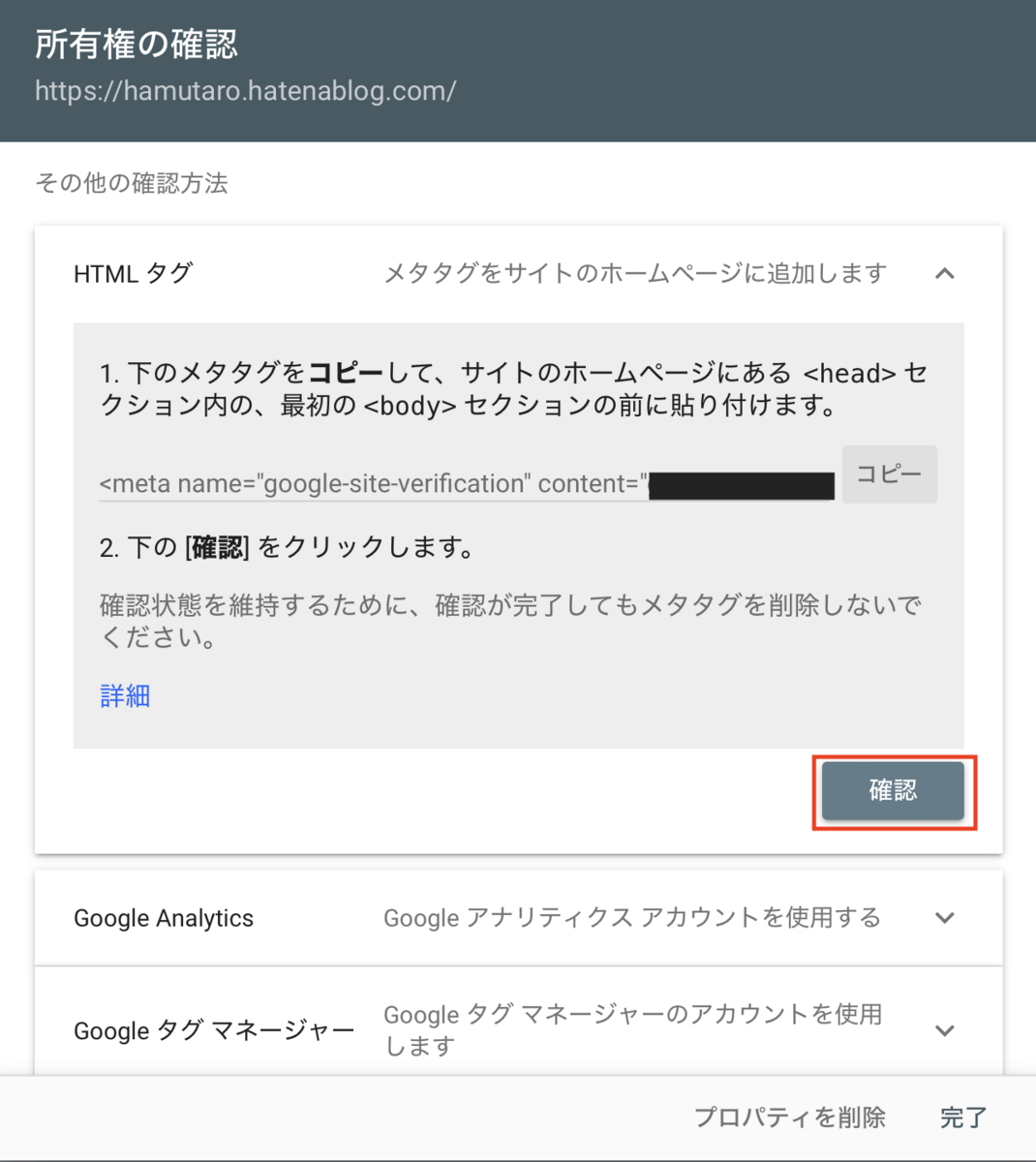
下記の画像で、「HTMLタグ」をクリックします。
※おすすめの確認方法である「HTML」ファイルは使用しないことに注意してください。

「HTMLタグ」をクリックすると、下記のような画面が出てきます。
 ↑画像の赤線部分(モザイク処理してある部分)をコピーします。
↑画像の赤線部分(モザイク処理してある部分)をコピーします。
※content="XXX"内のXXX部分(英数字の文字列)だけコピーすることに注意
続いて、コピーした英数字(HTMLタグ)を、はてなブログの設定画面に貼り付けます。
上記の画面は閉じずに、開いたままにしておいてください。
はてなブログにHTMLタグを貼り付ける
次に、はてなブログのダッシュボード画面を開き、①設定→②詳細設定をクリックします。

下の方にスクロールしていくと、下記の画像のように、「Google Search Console(旧Googleウェブマスターツール)」の入力欄が出てきます。
そちらに、先ほどコピーしたHTMLタグを入力します。

入力したら、画面を一番下までスクロールして、「変更する」を忘れずにクリック

Google Search Consoleに戻り、「確認」をクリック。
下記のように、「所有権を自動確認しました」と表示されれば成功です!
「プロパティに移動」をクリックします。
設定もあと少しなので頑張りましょう!

サイトマップを送信
 下記手順に沿って、サイトマップを送信します。
下記手順に沿って、サイトマップを送信します。
①. サイトマップをクリック
②. sitemap.xmlを入力
③. 「送信」をクリック

サイトマップの送信が完了すると、以下のように、「送信されたサイトマップ」にサイトマップの情報が追加されます。
ステータスが、最初は「取得できませんでした」だったのですが、少し時間をおいてページ更新を行ったところ、下記のように「成功しました」に変わりました。

[補足] 上記の画像だと、検出されたURLが0になっていて、「うまくいっているのか?」となっていましたが、数時間ほど時間を空けて再度ページを読み込むとページ数が更新されていました!なので、ステータスが「取得できませんでした」や、検出されたURLが0の場合は、一旦時間を空けてみるほうが良さそうです。
それでもうまくいかない場合は、下記の2つも送信することでうまくいくケースがあるみたいです。
今回は以上になります!
実際にまだ活用できていないので、使ってみての感想などまたまとめていきたいなと思います。
関数に付与されている"->"は何?アノテーションについて解説
アノテーションとは?
pythonのコードを見ていると、関数定義の箇所に"->"という記載があります。
例えば、こんな感じです。
def say_hello(name: str) -> None: print(f"Hello, {name}!") result = say_hello("Alice") print(result) # None
これは、「アノテーション」と言って、変数や関数の引数、戻り値に型情報を付けることで、コードの可読性や保守性を向上させるための機能です。
通常は、型名を記述する必要はありませんが、自分のコードを他人に見せたり、他人のコードを読む際に、コメントがあった方が親切だよね、という意味を込めて使われます。
色々と例を見ていこうと思います。
1. 変数のアノテーション:
name: str = "John" age: int = 25 height: float = 175.5
上記の例では、name 変数に str 型、age 変数に int 型、height 変数に float 型というアノテーションを付けています。
2. 関数の引数と戻り値のアノテーション:
def add_numbers(x: int, y: int) -> int: return x + y
上記の例では、add_numbers 関数の引数 x と y に int 型のアノテーションを付け、戻り値の型を int 型として指定しています。
3. クラスのメソッドのアノテーション:
class Person: def __init__(self, name: str, age: int): self.name = name self.age = age def greet(self) -> str: return f"Hello, my name is {self.name}!"
上記の例では、Person クラスの init メソッドの引数 name と age に str 型と int 型のアノテーションを付け、greet メソッドの戻り値の型を str 型として指定しています。
ここで1点注意ですが、アノテーションは処理の内容に影響しません。そのため、エラー回避などにはならないことには注意してください。
まとめ
Pythonのアノテーションは、変数や関数の引数、戻り値に型情報を付けることで、コードの可読性や保守性を向上させるための機能です。ぜひ使ってみてください。
uniqueメソッドの使い方
uniqueメソッドとは?
pandasの.unique()メソッドは、Seriesオブジェクト(列)内において、一意の値を取得するために使用されます。具体的には、重複する値を取り除き、データの一意の値のリストを返します。
実際に具体例を見てみましょう。
以下に.unique()メソッドの使い方と例を示します。
import pandas as pd # サンプルデータフレームの作成 data = {'Name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob'], 'Age': [25, 30, 35, 28, 32], 'City': ['Tokyo', 'Osaka', 'Tokyo', 'Kyoto', 'Tokyo']} df = pd.DataFrame(data) # Name列の一意の値を取得 unique_names = df['Name'].unique() print(unique_names)
出力
['Alice' 'Bob' 'Charlie']
この例では、df['Name']でName列を取得し、.unique()メソッドを使用して一意の値を抽出しています。結果として、'Alice'、'Bob'、'Charlie'の3つの値が取得できていることがわかります。
まとめ
.unique()メソッドは、データの特定の列内の一意の値を調べる際や、重複を取り除いた値のリストを作成する際に便利!
.unique()メソッド、皆さんも使っていきましょう〜!
groupbyメソッドの使い方
groupbyメソッドとは?
groupbyメソッドとは、Pandasのデータフレームやシリーズをグループ化するための強力なメソッドです。
.groupby()メソッドを使用することで、特定の列の値に基づいてデータをグループ化し、それぞれのグループに対して集計や操作を行うことができます。
以下に.groupby()メソッドの一般的な使い方といくつかの例を示します。
単一の列に基づくグループ化と集計
import pandas as pd # サンプルデータフレームの作成 data = {'Name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob'], 'Age': [25, 30, 35, 28, 32], 'Salary': [5000, 6000, 7000, 5500, 6500]} df = pd.DataFrame(data) # Name列でグループ化して平均年齢を計算 grouped = df.groupby('Name') average_age = grouped['Age'].mean() print(average_age)
出力
Name Alice 26.5 Bob 31.0 Charlie 35.0 Name: Age, dtype: float64
名前ごとに、'Age'が平均化されていることがわかります。
複数の列に基づくグループ化と集計
import pandas as pd # サンプルデータフレームの作成 data = {'Name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob'], 'Gender': ['Female', 'Male', 'Male', 'Female', 'Male'], 'Salary': [5000, 6000, 7000, 5500, 6500]} df = pd.DataFrame(data) # NameとGenderの組み合わせでグループ化して平均給与を計算 grouped = df.groupby(['Name', 'Gender']) average_salary = grouped['Salary'].mean() print(average_salary)
出力
Name Gender Alice Female 5250.0 Bob Male 6250.0 Charlie Male 7000.0 Name: Salary, dtype: float64
'Name'列と、'Gender'列の組み合わせでグループ化し、'Salary'を平均化しています。
複数の集計統計量の計算
import pandas as pd # サンプルデータフレームの作成 data = {'Name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob'], 'Age': [25, 30, 35, 28, 32], 'Salary': [5000, 6000, 7000, 5500, 6500]} df = pd.DataFrame(data) # Name列でグループ化して年齢の統計情報を計算 grouped = df.groupby('Name') summary_statistics = grouped['Age'].agg(['min', 'max', 'mean', 'median']) print(summary_statistics)
出力
min max mean median Name Alice 25 28 26.5 26.5 Bob 30 32 31.0 31.0 Charlie 35 35 35.0 35.0
この例では、'Name'列に基づいてグループ化を行い、各グループの年齢に対して、最小値・最大値・平均値・中央値を算出しています。
補足
上記の例において、グループ化されたデータは、for文を使うことで中身をそのまま取り出すことができます。
group_nameはグループの値、group_dataは対応するデータを表します。
for group_name, group_data in grouped: print(group_name) print(group_data)
出力
Alice
Name Age Salary
0 Alice 25 5000
3 Alice 28 5500
Bob
Name Age Salary
1 Bob 30 6000
4 Bob 32 6500
Charlie
Name Age Salary
2 Charlie 35 7000
まとめ
.groupby()メソッドは、Pandasのデータフレームやシリーズをグループ化するための便利なメソッドです。主な使い方としては以下の通りです。
- 単一の列に基づくグループ化: df.groupby('column_name')
- 複数の列に基づくグループ化: df.groupby(['column_name1', 'column_name2'])
- グループごとの集計統計量の計算: grouped['numeric_column'].agg(['mean', 'sum', 'count'])
- グループごとの操作: for group_name, group_data in grouped:
if文, for文などを用いて、「同じ名称だった場合、〜の処理を行う」など少し面倒な処理をせずとも、一発でグループごとに集約・計算ができ、非常に便利なため、機会があれば積極的に使っていきましょう!
pandasのデータフレーム内で、特定の文字が含まれる回数をカウントする
pandasのデータフレーム内で、特定の文字が含まれる回数をカウントする処理について考えてみます。
今回は、winemag-data-130k-v2.csvを用いて練習してみます。 ↓下記リンクからDL可能です。 (https://gist.github.com/clairehq/79acab35be50eaf1c383948ed3fd1129)
まずは、データを読み込みます。
import pandas as pd pd.set_option("display.max_rows", 5) reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0) reviews.head()

やりたいこと:descriptionの列で"tropical"という文字が出現する回数をカウント
結論からいくと、
n = reviews.description.map(lambda desc: "tropical" in desc).sum()
でカウントすることが可能です。 何やらmap, lambdaなど難しそうな文字が見られます。 それぞれ解説していきます。
mapとは
mapとは、簡単に言えば、「Series(1次元のデータ)の各要素に関数を適用するメソッド」のことをいいます。 Series(1次元のデータ)の各要素を二乗する処理を例に挙げてみました。
import pandas as pd numbers = pd.Series([1, 2, 3, 4, 5]) def square(x): return x ** 2 squared_numbers = numbers.map(square) print(squared_numbers)
numbersにmap(関数)を適用することで、for文など使わずにデータの処理を一括で行えるようです。 つまり、
n = reviews.description.map(lambda desc: "tropical" in desc).sum()
上記のコードは、descriptionのSeriesに対して、lambda desc: "tropical" in descの関数を適用しているということになります。
では、lambdaとは何なのでしょうか?
lambdaとは
lambdaとは、簡単に言えば、「無名(匿名)関数を作成するためのキーワード」です。
与えられた数値を2倍する処理を例に挙げてみました。
double = lambda x: x * 2 print(double(5)) # 出力: 10
lambdaは、「lambda 引数: 処理」で表されます。
上記の例で言うと、「5という数字を2倍する処理を行う」ということです。
このようにdefで関数を定義しなくても、1行で関数を定義できるようですね。
本題の処理に戻ってみると、
lambda desc: "tropical" in desc
というのは、descにはreviews.descriptionの要素が引数として与えられ、
その中に、"tropical"という文字が入っていた場合に、Trueを返すという関数ということですね。
イメージ的には、下記の通りです。
desc = "tropical orangina" print("tropical" in desc) # 出力: True
まとめ
特定の列に、条件に合う文字が入っている場合の回数をカウントする処理について見てきました。
n = reviews.description.map(lambda desc: "tropical" in desc).sum()
上記の処理は、
reviews.descriptionでdescriptionのデータを抽出
map()を使用することで、全要素にlambda desc: "tropical" in descという関数を適用
"tropical"という文字が入っていたら、Trueを返す
.sum()でTrueの個数をカウントする
という流れになります。
疑問点などあれば、コメントよろしくお願いします!